2025 全栈架构演进:从 Serverless 到 K8s,梦该醒了
作为一个全栈开发者,过去几年最让人心累的不是写代码,而是 技术选型。
左手是 Kubernetes 微服务全家桶,每个服务都要写 Dockerfile、Helm Chart 和 Service Mesh 配置。右手是 AWS/Vercel Serverless 全家桶,启动虽快,但冷启动、连接池耗尽、厂商锁定让人头秃。
到了 2025 年,风向变了。随着 Drizzle ORM、htmx、Next.js Server Actions 等技术的成熟,业界开始从“盲目拆分”回归“实用主义”。我们不再为了“像 Google 一样”去设计架构,而是为了“像独立开发者一样快速交付”。
1. 微服务已死?模块化单体 (Modular Monolith) 万岁
回望过去十年,微服务架构被过度神话了。我们见过太多只要 5 个人的研发团队,强行把系统拆成 20 个微服务。结果呢?
- 开发地狱:改一个字段要动 3 个仓库。
- 调试地狱:为了找一个 Bug,在 Jaeger 的分布式链路追踪里泡半小时。
- 事务地狱:简单的数据库 ACID 事务,变成了复杂的 TCC 或 Saga 最终一致性方案。
2025 年的主流架构是 模块化单体 (Modular Monolith)。

什么是模块化单体?
你在同一个代码库 (Repo) 里开发,作为一个整体部署(比如一个 Docker 容器或一个 Serverless Function)。但是,代码逻辑上有严格的边界。
在 NestJS 或 Spring Boot 中,这意味着你有 modules/auth, modules/payment, modules/order。
关键规矩:严禁模块间循环依赖。Order 模块不能直接 import User 模块的 Service,必须通过定义的 Public Interface 通信。
这样做的好处是鱼和熊掌兼得:
- 爽快的开发体验:IDE 跳转直达定义,重构方便,没有网络延迟。
- 爽快的部署体验:不用搞复杂的编排,一条 CI/CD 流水线搞定。
- 可扩展性:如果有一天你的 Payment 模块真的因为并发量巨大需要独立扩容,由于代码边界清晰,你可以非常轻松地把它剥离出来封装成微服务。
Shopify、GitHub、Stack Overflow —— 这些巨头在很长一段时间内都运行着巨大的单体。如果单体能支撑他们,大概率也能支撑你。
2. Serverless 数据库与“边缘化”
以前做 Serverless 最痛苦的是什么?连接池耗尽 (Connection Pool Exhaustion)。
当 AWS Lambda 瞬间扩容一千个实例同时启动,每个实例都试图去连接传统的 PostgreSQL (如 RDS)。PostgreSQL 的连接是进程级资源,很重,默认最大连接数可能就几百。结果就是数据库瞬间崩溃,拒绝服务。
为了解决这个问题,我们被迫配置 PgBouncer,买专门的数据库代理服务,又贵又复杂。
现在,Neon, PlanetScale, Turso (SQLite) 这类 Serverless 数据库彻底改变了局面。
HTTP is the New TCP
这些新一代数据库提供了基于 HTTP 的 API 接口或智能 WebSocket 代理。
- Neon:基于 PostgreSQL,计算存储分离。空闲时 0 费用 (scale to zero),连接数几乎无限。
- Turso:基于 SQLite 和 LibSQL。它把数据库变成了文件,通过 HTTP 在全球复制。这意味着你可以把数据库推送到离用户最近的 Edge 节点。
在 Edge Function 中访问数据库变得极其简单:
// Drizzle ORM + Turso
import { drizzle } from 'drizzle-orm/libsql';
import { createClient } from '@libsql/client';
const client = createClient({ url: process.env.DB_URL, authToken: process.env.DB_TOKEN });
const db = drizzle(client);
// 这次查询走的是 HTTP,而不是长 TCP 连接
const users = await db.select().from(usersTable).all();3. 边缘计算 (Edge Computing) 的退潮与理性回归
两年前,我们都在喊“Edge First”,恨不得把所有逻辑都推到边缘(Cloudflare Workers, Vercel Edge)。
但 2025 年,我们发现了一个尴尬的物理事实:光速是有限的。
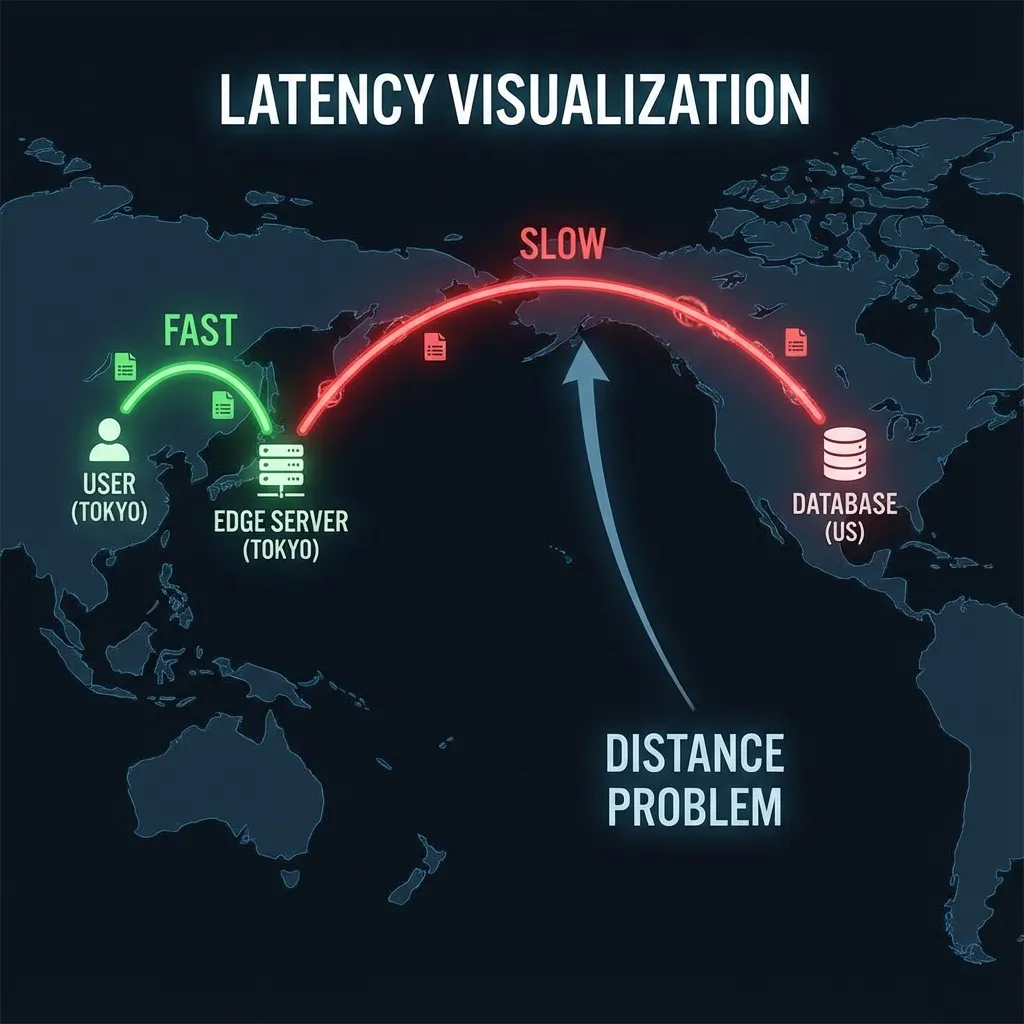
如果你的数据库在“美国弗吉尼亚 (us-east-1)”,而你的 Edge Function 在“日本东京”:
- 用户(东京)请求 Edge Function(东京)-> 极快 (10ms)。
- Edge Function(东京)查询数据库(弗吉尼亚)-> 极慢 (200ms)。
- 数据库返回数据 -> 极慢 (200ms)。
- Edge Function 返回给用户。
总耗时 400ms+。这叫 瀑布流延迟 (Waterfall Problem)。
如果你的后端是传统的单一 Region(比如就在弗吉尼亚):
- 用户(东京)请求后端(弗吉尼亚)-> 慢 (200ms)。
- 后端(弗吉尼亚)查询数据库(弗吉尼亚)-> 极快 (1ms, 内网)。
- 后端返回用户 -> 慢 (200ms)。
总耗时也是 400ms 左右,甚至因为数据库连接复用更快。
所以,除非你真的实现了 全球数据库复制 (Global Database Replication)(这很难,且有数据一致性延迟),否则 计算跟随数据 (Compute near Data) 才是性能最优解。
Edge 计算现在更多回归到了它擅长的领域:
- Auth 验证:JWT 校验,拦截非法请求。
- 简单路由:根据用户 IP 重定向到最近的主节点。
- 静态资源分发:HTML/CSS/JS/图片。
核心业务逻辑 (CRUD),正在回归中心化的 Region。
4. 全栈框架的统治:BFF 的消亡
以前我们讲 BFF (Backend for Frontend) 模式:为了适配 iOS、Android、Web 不同的数据需求,要在后端前面挡一层 GraphQL 或者专门的 API 层。
现在,以 Next.js、Remix、Nuxt 为代表的全栈框架,实际上把 BFF 内化了。
当你在 Next.js 里写一个 Server Action,或者在 Remix 里写一个 Loader,你本质上就是在写 BFF。你在组件文件的旁边直接写后端逻辑,直接 import ORM 查数据库,然后把清洗好的数据传给组件。
不需要定义 RESTful URL,不需要写 Swagger 文档,不需要定义 JSON Schema。前端组件和后端取数逻辑紧密耦合 (Co-location),开发效率提升了十倍不止。
现在的“后端开发”,很多时候不是在维护一个独立的 Golang/Java 服务,而是在全栈框架的 /app 目录下写 Service 层逻辑。
总结
2025 年的后端架构哲学是:Keep it Simple, Make it Scale.
- 默认选模块化单体:别一上来就微服务。
- 拥抱 Serverless DB:数据库运维的脏活累活丢给云厂商,只管连。
- 计算跟随数据:除非有全球一致性数据库,否则别盲目上 Edge。
- 全栈框架优先:让 React/Vue 框架接管你的路由和取数层。
