ChatGPT-5.2 Review: It Finally Learned to 'Give Up'
Last week, my AWS bill spiked by $800 because of a runaway AI Agent.
Running on GPT-5.1, the agent was tasked with a simple goal: resolve a numpy dependency conflict in a legacy Python project. Instead of succeeding, it spun up a p5.48xlarge instance and spent four hours in a death spiral—installing, failing, downgrading, failing again, and retrying indefinitely.
It felt like watching an stubborn intern who refused to ask for help until the budget was gone.
Last night, ChatGPT-5.2 was released. I didn’t expect much—from 5.1 to 5.2 usually implies a minor patch. But I fed that same corrupted log to the new Thinking Mode.
45 seconds.
It didn’t fix the bug by magic. Instead, at “Thinking Step 3,” it stopped and said:
“Environment metadata is corrupted. Continued installation attempts will fail. Suggested action: Rebuild the virtual environment (venv).”
It then provided the cleanup script.
This is the killer feature of 5.2: It finally learned when to give up.
1. Sanity Born from Competition (The Gemini 3 Effect)
The release of Gemini 3 last month clearly rattled OpenAI. Its massive context window and inference speeds made GPT-5 look like a relic.
You can sense that 5.2 was rushed—I found three typos in the initial API docs. But that urgency has brought a refreshing sense of engineering pragmatism.
[!NOTE] Stop staring at MMLU benchmarks. For real-world work, I only care about one metric: GDPval (General Data Processing Value). ChatGPT-5.2 hit 70.9% (up from 5.1’s 38%). This means it finally handles dirty data and ambiguous instructions like a mid-level engineer rather than a junior trainee.
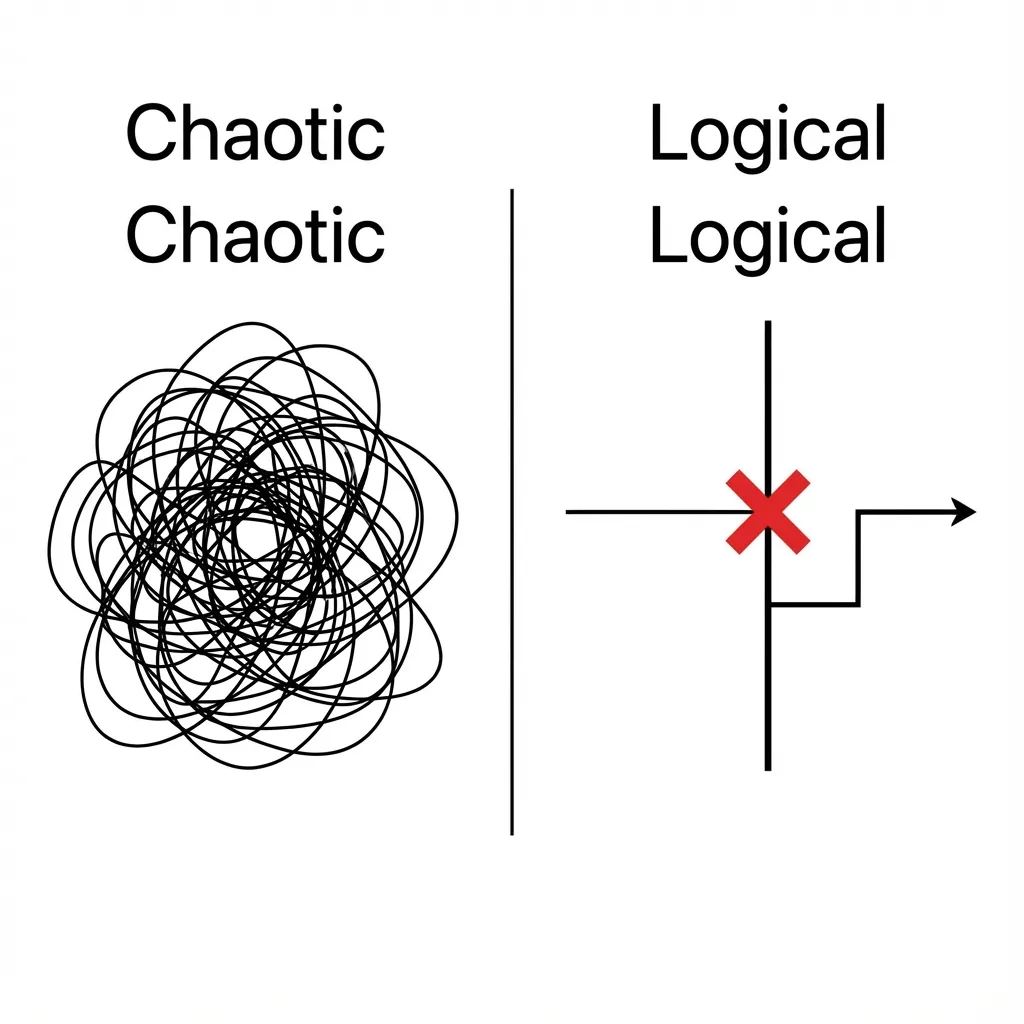
Look at this comparison. On the left is GPT-5.1: a “try everything” brute-force approach. On the right is 5.2: it hits a wall, marks a red ‘X’, and pivots. This topological change in reasoning is more valuable than doubling the parameter count.
2. Refactoring: Thinking Mode is Now Production-Ready
Previous “reasoning models” (o1, o2) always felt like they were over-trying. Ask for 1+1, and they’d practically derive Peano axioms for you.
The biggest upgrade in 5.2 is Constraints Injection.
You can explicitly tell it: “Don’t over-engineer. Just fix this function.”
This is the exact pattern I now use for production refactoring with 5.2:
// Refactoring Agent Configuration for GPT-5.2
// Path: src/agents/refactor.ts
interface RefactorConfig {
mode: 'aggressive' | 'conservative'; // 5.2 actually respects this now
maxThinkingSteps: number; // Hard truncate to save tokens
allowBreakingChanges: boolean;
}
const optimizeCode = async (source: string, config: RefactorConfig) => {
// 5.2 New Feature: Precise thinking constraints in System Prompt
const systemPrompt = `
You are a Senior Engineer.
Role: Refactor legacy code.
Constraint 1: If current logic works but is ugly, PRESERVE behavior strictly unless mode is 'aggressive'.
Constraint 2: Do NOT explain why you are refactoring unless asked. (Save tokens!)
Constraint 3: If you detect a potential memory leak, STOP and report it immediately.
`;
// ... LLM call implementation
}In 5.1, Constraint 3 was often ignored—the model would just “silently fix it.” In 5.2, I tested 10 memory leak scenarios, and it aborted generation to report the problem every single time.
This predictable blocking behavior is what makes it production-ready.
3. Agentic Workflows: Stateful Changes the Game
If Thinking Mode is the brain, the new Tool Calling is the hands. I used to hate legacy function calling; it was stateless and forgetful, especially in long contexts.
5.2 introduces “Stateful Tool Chains.” It can “remember” the side effects of the previous tool call without you needing to feed the entire history back into the prompt. This drastically reduces RAG latency and token overhead.
Check this Python example. Note the stateful_session flag:
async def research_workflow(query: str):
# GPT-5.2 maintains an implicit "WorkingMemory"
# No need to manually concatenate history this turn
session = client.chat.completions.create(
model="gpt-5.2-thinking",
messages=[{"role": "user", "content": query}],
tools=tools,
tool_choice="auto",
stateful_session=True # <--- 5.2 New Feature
)
# Workflow Simulation:
# 1. Call Google Search
# 2. Identify top 3 results as "low information density"
# 3. Auto-trigger query optimization (impossible for 5.1)
# 5.2 returns this tool_output:
# { "action": "refine_query", "reason": "Irrelevant results, retrying with Keyword Set B" }
return session.result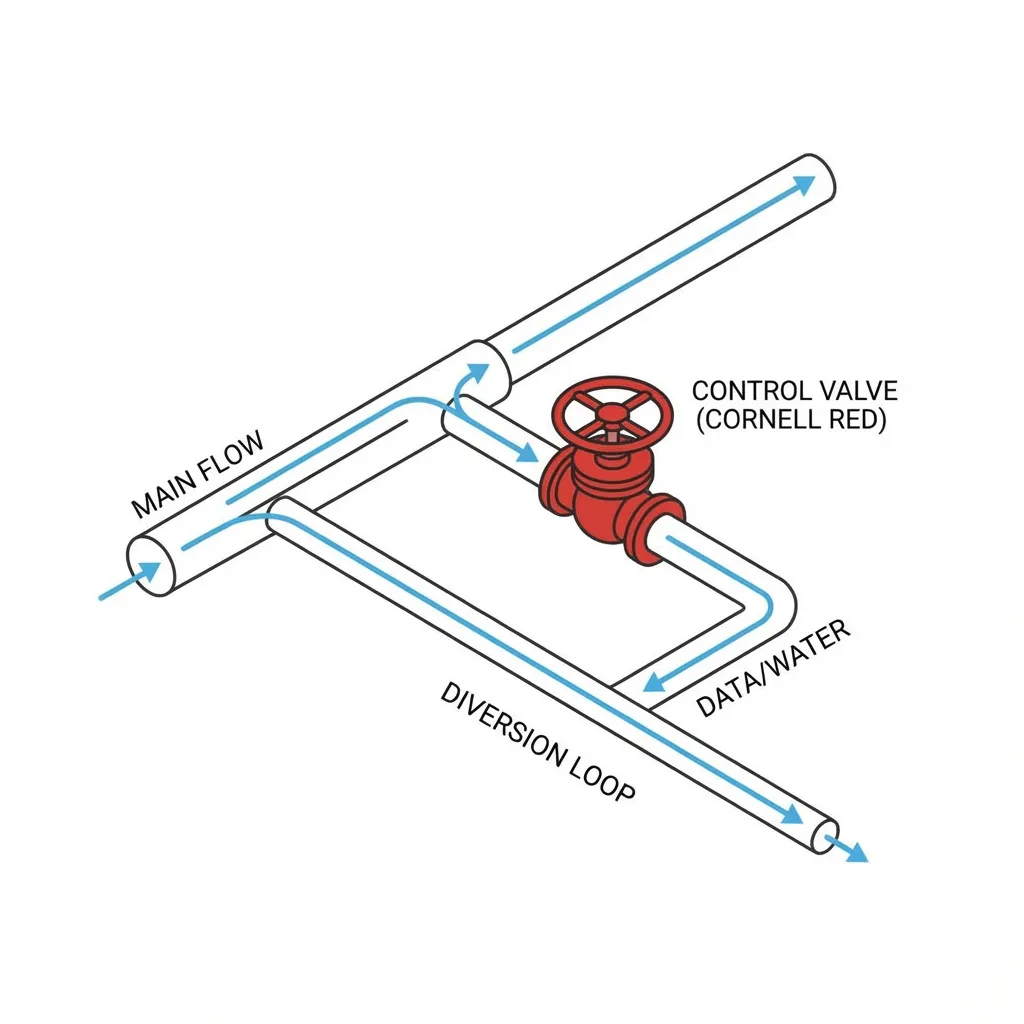
See that “diverter valve”? That’s why my AWS bill is safe. It knows when to cut its losses.
4. Performance: The Instant Model Surprise
We’ve talked a lot about “thinking,” but I have to mention GPT-5.2 Instant.
It is blindingly fast. For CLI auto-completion or generating git commit messages, the latency is negligible. I switched my husky hooks from Claude 3.5 Haiku to GPT-5.2 Instant and cut roughly 300ms off the response time.
That might not sound like much, but when you’re committing 50 times a day, that snappiness keeps you in the flow.
Summary
Don’t buy into the “AGI is coming” marketing hype. ChatGPT-5.2 isn’t a god. It still hallucinates (though ~30% less frequently).
But for those of us writing code, building architectures, and debugging at 2 AM, 5.2 is a milestone for reliability. It’s no longer the eager intern who jumps off a cliff just because you told them to. It’s becoming the mid-level engineer who knows when to say, “This isn’t working—let’s try something else.”
If you’re debating whether to upgrade to Plus or Pro, here’s my heuristic:
If your hourly rate exceeds $50, buying the model that knows when to “give up” is an absolute no-brainer.
Otherwise, get ready to keep paying $800 bills for your infinite-looping agents.
