别再写 'Act as a...' 了: prompt 已经死了,编程才是未来

我以为我掌握了 Prompt Engineering 的精髓。
直到上周,我那个跑了三个月的客服机器人突然开始给用户推荐“竞争对手的产品”。排查了半天,发现仅仅是因为 OpenAI 更新了模型权重,导致我那段精心雕琢的、长达 500 字的 systemic prompt 失效了。
我当时就想把电脑砸了。
我们在构建现代软件,却在用类似“求神拜佛”的方式在跟核心组件沟通。如果你还在花几个小时微调“请用温柔的语气”或者“深呼吸,一步步来”,恭喜你,你正在做无用功。
Prompt Engineering (提示词工程) 是个伪命题。未来属于 Prompt Programming (提示词编程)。

为什么你的 Prompt 总是崩?
手动写 Prompt 的最大问题是不可预测性。自然语言是模糊的,而软件工程需要精确。
当你写下 You are a helpful assistant 时,你实际上是在赌博。你赌模型的训练数据里包含了你想要的“helpful”的定义。但只要模型版本一变,或者 Temperature 稍微抖动一下,你的积木就塌了。
玄学调优(Vibe Checking)不是工程。如果你的系统依赖于具体的措辞,那它就是脆弱的。
方案一:强制结构化输出 (Structured Output)
别再让 LLM 返回纯文本了。那是给人看的,不是给程序读的。
如果你还在用正则表达式去匹配 LLM 的输出,请立刻停手。现代 LLM (GPT-4o, Claude 3.5 Sonnet) 都支持 Native 的结构化输出。
这是我生产环境中实际使用的 Python 代码,配合 Pydantic 和 Instructor:
import instructor
from pydantic import BaseModel, Field
from openai import OpenAI
# 定义你想要的严格数据结构
class UserIntent(BaseModel):
category: str = Field(..., description="用户的意图分类,必须是 ['Refund', 'Support', 'Sales'] 之一")
urgency: int = Field(..., description="紧急程度,1-10,10为最紧急")
reasoning: str = Field(..., description="判断理由的思维链 (CoT)")
client = instructor.from_openai(OpenAI())
def analyze_request(user_input: str) -> UserIntent:
return client.chat.completions.create(
model="gpt-4o",
response_model=UserIntent,
messages=[
{"role": "system", "content": "你是一个严谨的意图分类器。"},
{"role": "user", "content": user_input},
],
)
# 即使模型想废话,它也只能被迫返回 JSON
result = analyze_request("我刚买的会员完全不能用,立刻给我退钱!")
print(result.json(indent=2))
# {
# "category": "Refund",
# "urgency": 10,
# "reasoning": "用户使用了'立刻'和感叹号,且涉及金钱交易,情绪激动。"
# }看到 reasoning 字段了吗?这是关键。让模型先输出思维链,再输出分类结果,准确率能提升 30% 以上。但这不再是“提示词技巧”,这是类型系统 (Type System) 的胜利。
方案二:让模型自己优化 Prompt (DSPy)
如果手动写 Prompt 很蠢,那谁来写?答案是 AI 自己。
斯坦福大学搞出来的 DSPy 是目前最硬核的框架。它的核心理念极其反直觉:不要写 Prompt,要定义签名 (Signatures) 和 优化器 (Optimizers)。
这就好比从汇编语言进化到了 C 语言。你告诉 DSPy 你的输入是什么,输出想要什么,给它几个例子(Few-shot),然后 DSPy 会自己去编译出最优的 Prompt。
看看这个对比,这才叫工程化:
import dspy
# 1. 定义签名 (Signature) - 类似于函数接口
class Summarizer(dspy.Signature):
"""Summarize the text into a concise tweet."""
article_content = dspy.InputField()
tweet = dspy.OutputField(desc="under 280 chars, engaging")
# 2. 定义模块 (Module) - 类似于神经网络层
class TweetBot(dspy.Module):
def __init__(self):
super().__init__()
self.generate = dspy.ChainOfThought(Summarizer)
def forward(self, article_content):
return self.generate(article_content=article_content)
# 3. 编译 (Compile) - 这步最这神奇
# 将 teleprompter 设置为 BootstrapFewShot,它会自动从训练集中寻找最佳例子塞进 Prompt
from dspy.teleprompt import BootstrapFewShot
# 假设 trainset 是一堆 (文章, 好推文) 的例子
optimizer = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_bot = optimizer.compile(TweetBot(), trainset=my_dataset)
# 现在 compiled_bot 内部包含了一个经过数学优化的 Prompt
compiled_bot(article_content="DSPy is amazing...")当你用 DSPy 时,你不再关心 Please 这个词放哪里更好。你关心的是数据集的质量和评估指标 (Metric)。这才是程序员该干的事。
方案三:自省循环 (The Refinement Loop)
就算有了结构化输出和 DSPy,模型偶尔还是会发疯。这时候你需要自省。
我在 n8n 里搭建这类工作流时,永远不会只调一次 LLM。我会设计一个 Generator -> Critic -> Refiner 的闭环。
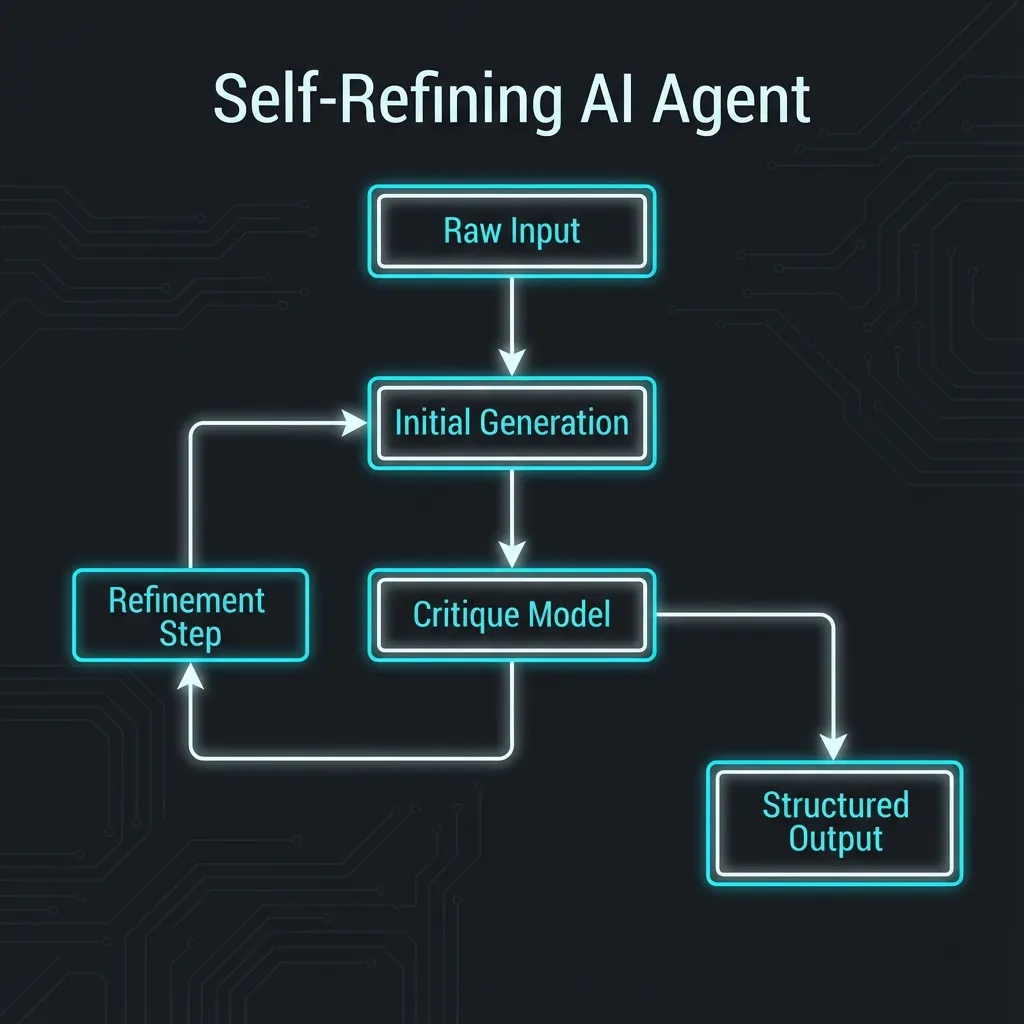
- Generator: 快速生成初稿。
- Critic: 扮演“苛刻的 Code Reviewer”,检查初稿是否有逻辑漏洞或安全风险。
- Refiner: 根据 Critic 的意见修复初稿。
这比你写一句 Please ensure correctness 管用一万倍。因为你把“检查”这个动作显式地变成了一个计算步骤,而不是一句空洞的指令。
总结
别再沉迷于收集“100个神级 prompt 模板”了。那都是快过期的垃圾。
真正的 Prompt 高手,都在写 Python 代码,都在设计 JSON Schema,都在构建自动化评估管线。
- 用 Pydantic/Zod 约束输出。
- 用 DSPy 优化流程。
- 用 n8n 编排闭环。
这才是 2025 年该有的样子。其他的一切,都是玩具。
