Stop Saying 'Act as a...': Prompting is Dead, Programming is the Future

I thought I had mastered Prompt Engineering.
Then last week, my customer service bot—which had been running flawlessly for three months—suddenly started recommending a competitor’s product to our users. After hours of debugging, I discovered the cause: OpenAI had updated a model weight, making my carefully crafted, 500-word system prompt obsolete overnight.
I nearly threw my laptop out the window.
We are building modern software, yet we are communicating with our core components through what is effectively “thoughts and prayers.” If you are still spending hours fine-tuning phrases like “please use a professional tone” or “take a deep breath,” you are working on borrowed time.
Prompt Engineering is a dead end. The future belongs to Prompt Programming.
Why Your Prompts Constantly Break
The fundamental problem with manual prompting is unpredictability. Natural language is ambiguous, while software engineering requires precision.
When you write You are a helpful assistant, you are gambling. You are betting that the model’s training data matches your specific definition of “helpful.” But the moment the model version changes or the temperature fluctuates, your house of cards collapses.
Vibe Checking is not engineering. If your system depends on specific phrasing, it is brittle by design.
Solution 1: Mandatory Structured Output
Stop letting LLMs return raw text. That’s for humans, not for programs. If you are still using regex to parse LLM responses, stop immediately. Modern LLMs (GPT-4o, Claude 3.5 Sonnet) support native structured outputs.
Here is the Python pattern I use in production, paired with Pydantic and Instructor:
import instructor
from pydantic import BaseModel, Field
from openai import OpenAI
# Define your strict data structure
class UserIntent(BaseModel):
category: str = Field(..., description="Intent classification. Must be ['Refund', 'Support', 'Sales']")
urgency: int = Field(..., description="Urgency level, 1-10, where 10 is critical")
reasoning: str = Field(..., description="The Chain of Thought (CoT) logic for this choice")
client = instructor.from_openai(OpenAI())
def analyze_request(user_input: str) -> UserIntent:
return client.chat.completions.create(
model="gpt-4o",
response_model=UserIntent,
messages=[
{"role": "system", "content": "You are a precise intent classifier."},
{"role": "user", "content": user_input},
],
)
# The model is forced to return valid JSON, no matter what
result = analyze_request("My membership isn't working despite paying. Refund me now!")
print(result.json(indent=2))
# {
# "category": "Refund",
# "urgency": 10,
# "reasoning": "User used 'now' and exclamation marks. Involves a transaction failure."
# }See the reasoning field? That is the hallmark of real engineering. Forcing the model to output its CoT before the final classification increases accuracy by over 30%. This isn’t a “prompt trick”; it’s the victory of a Type System.
Solution 2: Automated Optimization with DSPy
If manual prompting is a fool’s errand, who should write the prompts? The AI itself.
Stanford’s DSPy is the most rigorous framework available today. Its philosophy is counter-intuitive: Don’t write prompts; define Signatures and Optimizers.
This is the jump from assembly language to C. You define the input, the desired output, and provide a few examples. DSPy then “compiles” the optimal prompt for your specific model.
Look at this comparison—this is true engineering:
import dspy
# 1. Define Signature - The 'Interface'
class Summarizer(dspy.Signature):
"""Summarize the text into a concise tweet."""
article_content = dspy.InputField()
tweet = dspy.OutputField(desc="under 280 chars, engaging")
# 2. Define Module - The 'Layer'
class TweetBot(dspy.Module):
def __init__(self):
super().__init__()
self.generate = dspy.ChainOfThought(Summarizer)
def forward(self, article_content):
return self.generate(article_content=article_content)
# 3. Compile - The Magic Step
# BootstrapFewShot automatically finds the best examples to inject
from dspy.teleprompt import BootstrapFewShot
optimizer = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_bot = optimizer.compile(TweetBot(), trainset=my_dataset)
# compiled_bot now contains a mathematically optimized prompt
compiled_bot(article_content="DSPy is a foundational shift...")When you use DSPy, you stop caring where the word Please should go. You care about dataset quality and your evaluation metrics. That is where an engineer’s focus belong.
Solution 3: The Refinement Loop (Generator-Critic)
Even with structured outputs and DSPy, models can occasionally go off the rails. You need introspection.
When I build workflows in n8n, I never call an LLM once. I design a Generator -> Critic -> Refiner loop.
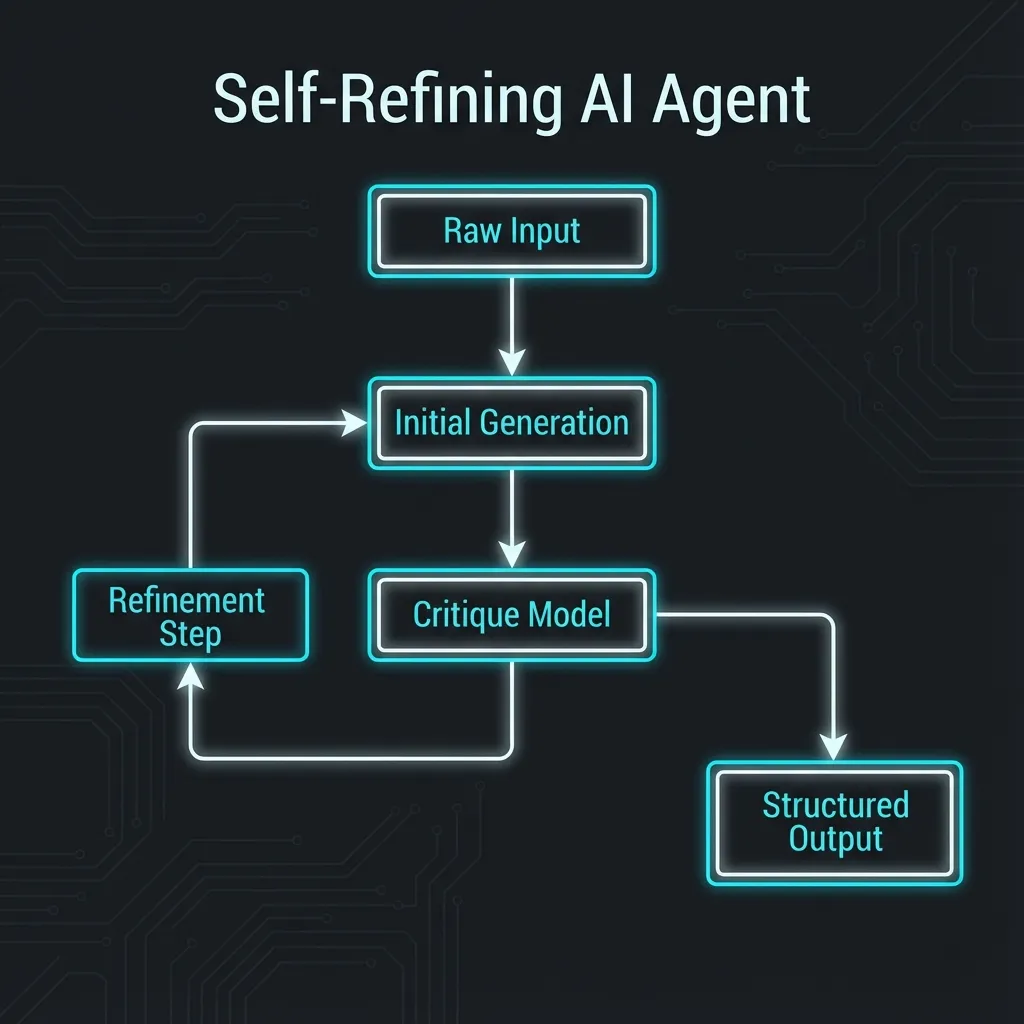
- Generator: Rapidly generates the first draft.
- Critic: Plays the “harsh Code Reviewer,” checking for logic gaps or security risks.
- Refiner: Fixes the draft based on the Critic’s objective feedback.
This is infinitely more effective than saying “Please ensure correctness,” because it turns “checking” into an explicit computational step.
Conclusion
Stop collecting “100 God-tier Prompt Templates.” They are garbage the moment the next update drops.
The true masters of AI aren’t writing clever phrases; they are writing Python, designing JSON Schemas, and building automated evaluation pipelines.
- Enforce constraints with Pydantic/Zod.
- Optimize logic with DSPy.
- Orchestrate loops with n8n.
This is what 2025 looks like. Everything else is a toy.
