autoresearch Does Not Really Rewrite Training Code. It Rewrites Research Operations

Most people see autoresearch for the first time and classify it as a repository for letting AI run its own hyperparameter search.
That is not wrong. It is just not the most important thing about it.
After reading the repository carefully, completing uv sync locally, and running the minimum data-preparation path, my stronger conclusion is this: autoresearch does not mainly rewrite training code. It rewrites the control surface of research work.
The most valuable idea in the repository is not that an agent edits train.py. It is that the repository turns the research manager into program.md, then locks the rest of the loop behind a small number of explicit engineering boundaries.
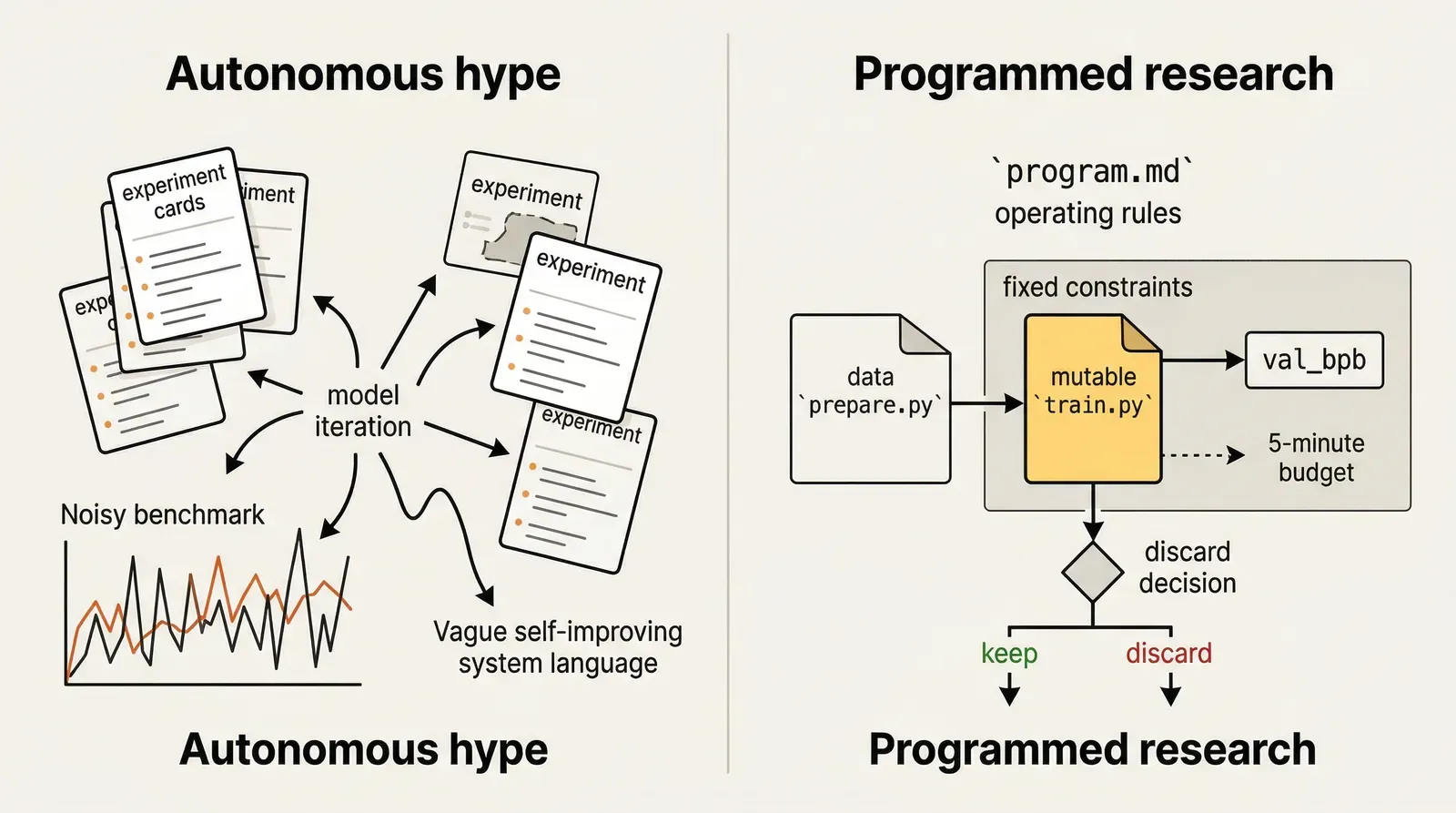
The real product interface is program.md
If you only read the README, it is easy to frame autoresearch as a lightweight autonomous research demo.
That interpretation breaks down as soon as you read program.md.
The file makes the actual operating model explicit:
- the human edits
program.md - the agent edits
train.py prepare.pyfixes the data, tokenizer, dataloader, and evaluation utilitiesval_bpbdecides whether an experiment is actually better
That division matters.
autoresearch is not really saying, “hand research over to the model.” What it is really saying is something narrower and much more serious: first turn research organization into a program, then let the agent operate inside that program’s boundary conditions.
That is why I think of this repository as programmed research management, not as an automated tuning script.
The smartest decision in the repository is how small it keeps the experimental surface
At its core, autoresearch only really has three files that matter:
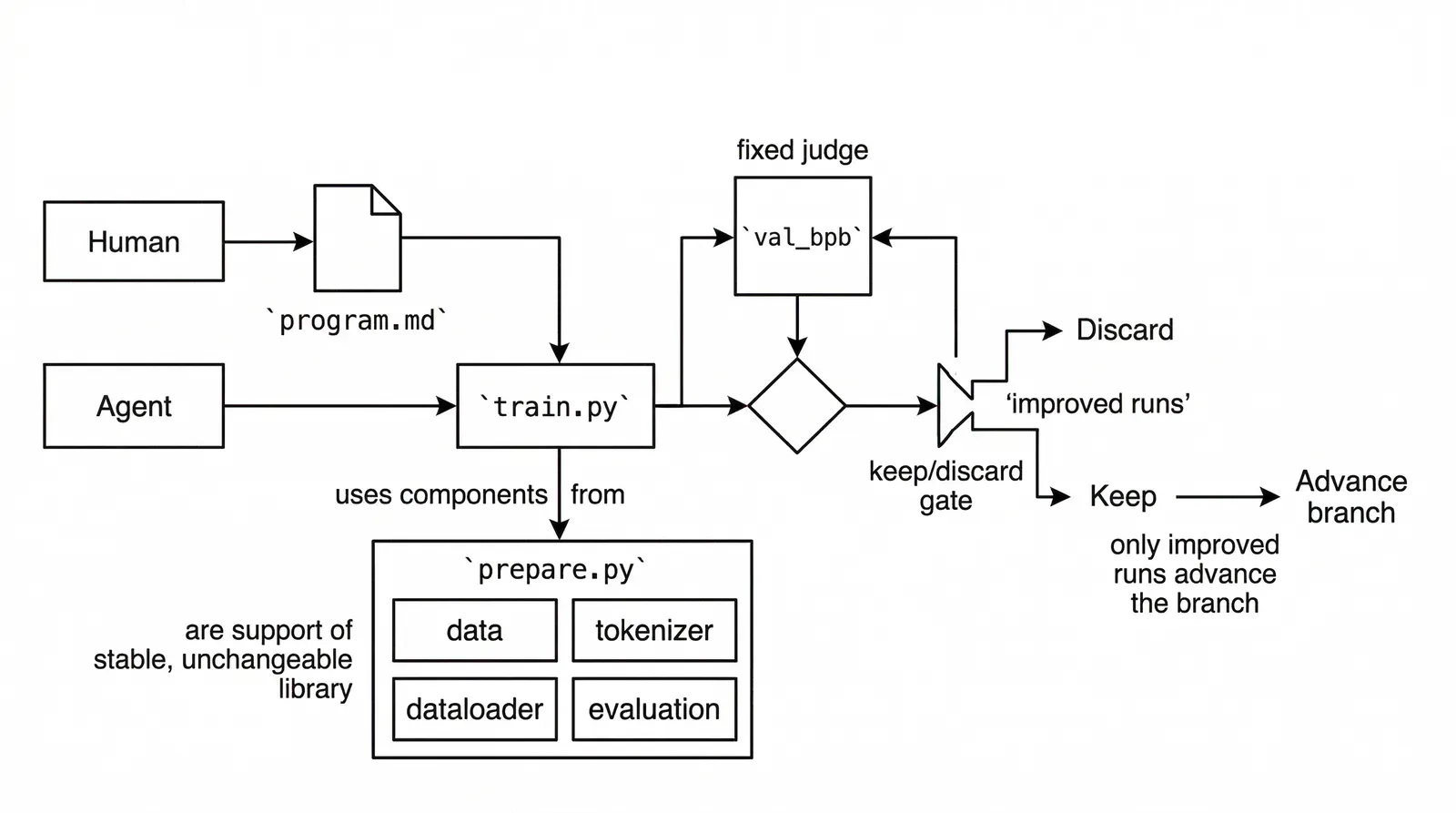
prepare.py: fixed constants, data preparation, tokenizer, dataloader, evaluationtrain.py: the only file the agent is supposed to modify repeatedlyprogram.md: the branch rules, logging discipline, keep-or-discard logic, crash handling, and the “never stop” experiment loop
This cut is unusually strong.
A lot of “AI does research automatically” projects open too many variables at once. Data changes. Evaluation changes. model structure changes. orchestration changes. dependencies change. prompt scaffolding changes. The result is a system that produces activity without producing comparability.
autoresearch makes the opposite move:
- It compresses agent-side change into a single core file.
- It fixes the judge as
val_bpb, while also fixing the training budget at five minutes.
Once those two constraints are in place, experiments start to behave like experiments instead of improvised code edits.
You may dislike the default model choices. You may dislike the Flash Attention dependency. You may dislike the single-GPU assumption. But it is difficult to deny that the research boundary is clear. Each change becomes easier to compare, and each failed idea becomes easier to discard.
The five-minute budget is not an implementation detail. It is the research protocol
One of the most important design decisions in the repo is also one of the easiest to underestimate: every training run gets the same five-minute wall-clock budget.
That is not just a convenience feature.
It solves a real research-process problem: once model size, batch size, attention pattern, optimizer choice, and training schedule are all moving at the same time, what does “fair comparison” even mean?
autoresearch answers that question very directly:
- do not compare by step count
- do not compare by epoch count
- do not compare by a fixed model family
- compare by the same wall-clock budget on the same machine
That has a practical consequence.
If an agent can run a dozen experiments overnight, you do not wake up to a pile of unrelated diffs. You wake up to a chain of trials advanced along one budget regime. The design fits an overnight loop naturally, and it fits a branch model where improvements are kept and regressions are thrown away.
From a workflow perspective, that is more mature than many repositories that try to place agents into research settings. The point is not openness. The point is comparability.
train.py exposes the real research surface
Another strong design choice is that train.py gives the agent a large enough research surface without dissolving into framework sprawl.
From the local code, the agent can directly change:
- the relationship between depth and model width
- head design and window pattern decisions
- optimizer mix and learning rates
- weight decay, warmdown, and batch sizing
- value embeddings, rotary embeddings, MuonAdamW, and other training details
That means this is not a shell that only lets the model tweak a handful of config values. It exposes the full training implementation, but forces all research moves to stay inside one file.
That matters because many “automatic experimentation platforms” go in the opposite direction. They add layers of configuration, abstraction, and orchestration until the system looks general while the actual experiment logic becomes harder to audit.
autoresearch makes a sharper trade-off: do not optimize for platform breadth first. Optimize for overlap between the research surface and the review surface.
That is a serious repo-level judgment, and I think it is the right one for a project at this stage.
But this is not a general research platform, and it is not a drop-in tool
This is where the article needs to cool down.
I do not think autoresearch should be described as a mature autonomous research system. Right now it reads more like a very sharp prototype with a clear thesis.
Its boundaries are obvious:
- it assumes a single NVIDIA GPU
- the README explicitly frames H100 as the tested target
- the main path depends on Flash Attention 3 kernels
- the evaluation target is a single metric:
val_bpb - it is not trying to solve distributed orchestration or cross-machine comparability
- the most important part of the research logic still has to be written by the human in
program.md
So the project does not eliminate research judgment. It relocates research judgment.
Instead of asking the human to hand-edit training code all night, it asks the human to define the research constitution up front. That is both the strength of the project and the point many readers will miss.
Local verification makes that boundary even clearer
To avoid repeating the README as if it were proof, I ran a minimal local verification loop on this machine:
- Windows
NVIDIA GeForce RTX 3060 Laptop GPU- 6 GB VRAM
The result split cleanly into what worked and what did not.
The path that worked:
git clonesucceededuv syncsucceededuv run prepare.py --num-shards 2 --download-workers 2succeeded- data download, tokenizer training, and token-bytes construction all completed locally
The path that failed:
- default
uv run train.pydid not reach actual training - the failure was not an exploding loss
- the failure was not an out-of-memory event
- the failure happened because
kernels-community/flash-attn3did not expose a matching build variant for this Windows environment
That is an important result.
It means the main repository is more accurately understood today as a reference implementation of a research operating model than as a truly portable drop-in tool. The README already links to Windows, Mac, and AMD forks, but that only reinforces the deeper point: the transferable idea and the ready-to-run implementation are not the same thing here.
If you are evaluating the repository seriously, the right sequence is not “install it and hope it works.”
The right sequence is:
- understand why the workflow boundary is designed this way
- decide whether that boundary is worth porting into your own environment
- only then solve kernels, platform compatibility, and smaller-VRAM tuning
The most reusable thing here is not the default code. It is the workflow contract
If I were borrowing from autoresearch, I would not start with a training trick.
I would start with these design rules:
- compress the agent’s write surface into a very small number of high-leverage files
- keep evaluation fixed so experiments cannot rewrite the judge
- use a fixed time budget to preserve comparability on one machine
- log keep-or-discard outcomes so branch advancement remains legible
- externalize the “keep experimenting” rule instead of rediscovering process discipline in every prompt
That pattern is not only useful for LLM pretraining.
The same problem appears in ranking systems, search systems, compiler optimization, data pipelines, and more general agentic coding loops. Without a strong enough procedural boundary, an agent quickly shifts from autonomous exploration into autonomous production of incomparable change.
That is the problem autoresearch refuses to ignore.

Final judgment
autoresearch still has plenty of edges that are not yet product-grade.
Its hardware assumptions are narrow. Its kernel dependency is heavy. The mainline implementation is less portable than the attention around it might suggest. If you treat it as a research product that everyone can run immediately, you will probably be disappointed.
But if you treat it as a design pattern for building an agent-facing research control surface, it becomes much more valuable.
That is the level where I think the repository is genuinely interesting.
My conclusion is simple:
The real invention in autoresearch is not that AI edits training code. It is that research operations themselves become programmable, comparable, and advanceable.
That is a much more serious idea than just another autonomous AI demo.
