Agent Architecture Is Everything: Lessons from 2 Months of Hermes & OpenClaw
In agentic development, the raw intelligence of large language models is rarely the primary bottleneck.
The actual ceiling of production-grade systems is determined by the engineering architecture. Over the past two months of deploying Nous Research’s Hermes Agent and the autonomous assistant OpenClaw in financial and investment workflows, we verified a clear consensus: Building useful agents is 90% architecture and 10% AI. Most failures stem from tools fighting each other, not the model being too dumb.
TL;DR: This article analyzes six architectural lessons learned from running Hermes in production, covering API router overheads, skill auto-evolution, memory routing, x402 micropayments, and codebase structure. Implementing these practices reduced context usage and prevented main-thread execution timeouts.
1. The Core Bottleneck: Tool Collisions & Deadlocks
When running complex data extraction or research pipelines, agents tend to fail due to tool contention rather than logical errors.

Injecting dozens of MCP (Model Context Protocol) endpoints into a single context often causes systemic failures:
- Resource Lockups: Two tools attempting to write to the same temporary workspace or network port simultaneously.
- State Corruption: One tool emitting non-standard markdown or JSON that breaks the parser of the next tool.
- Context Bloat: Feeding all operational rules into a massive, monolithic prompt, causing the model to misinterpret priority.
The solution requires isolating tool execution into sandboxed, single-purpose skill packages rather than relying on a single, growing system prompt.
2. API Router Overheads & Latency (Model Lesson)
In 60 days of development, we rotated through 5-6 model routing services and direct providers, revealing a significant tax on latency and reliability.
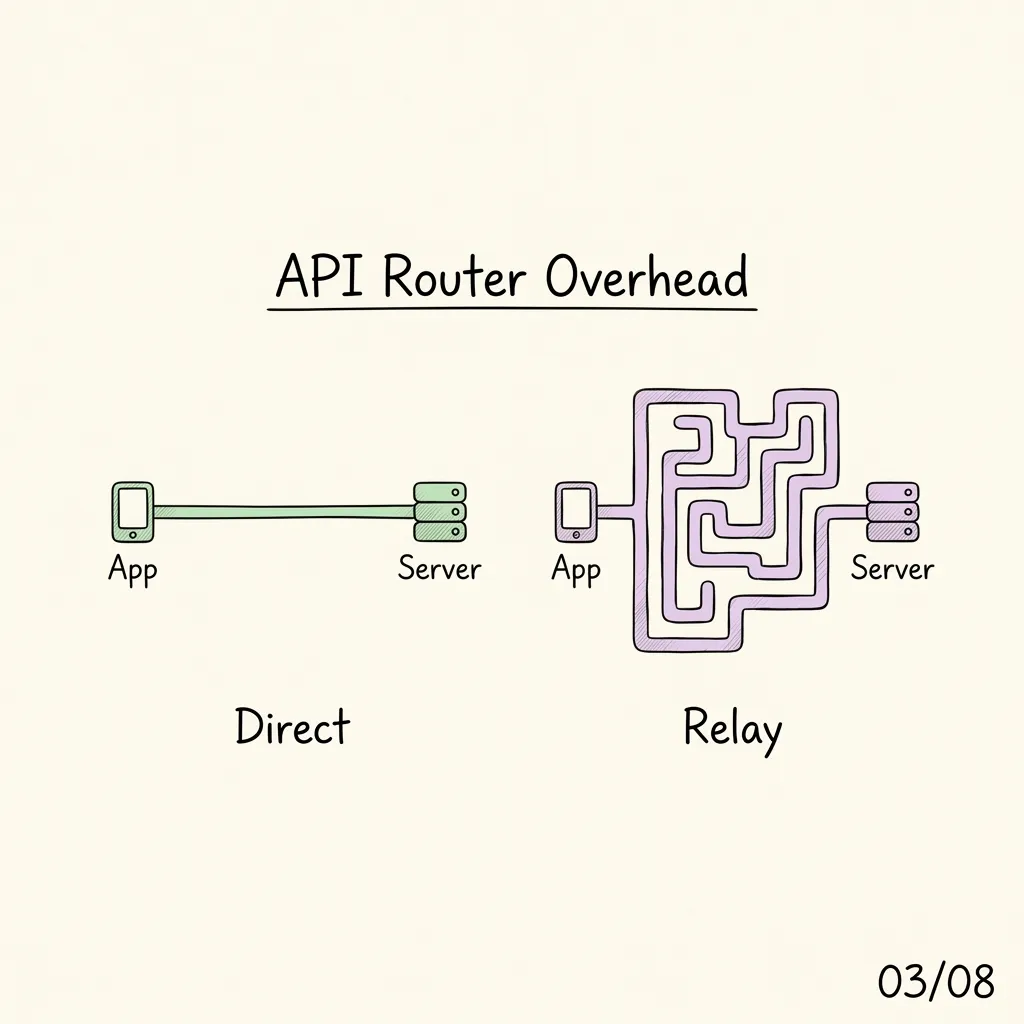
- Routing Hops: Multi-hop proxy services added 5 to 10 seconds of latency to every inference turn.
- Debugging Cost: Swapping providers meant debugging API compatibility, authentication quirks, and custom timeout configurations across different endpoints.
Workflow Comparison:
Relayed Path: Request → Aggregator → Secondary Router → Model (12-15s, High Jitter)
Direct Path: Request ────────────────────────────────→ Model (2-3s, Stable & Cheap)Engineering Verdict: Since open-weight models have reached parity with commercial frontier models for standard reasoning, the most optimal architecture is to bind your system to a single, direct API provider (e.g., DeepSeek direct) and stick with it. Direct connectivity yields better stability and lower operational costs.
3. Core Concept: Skill Auto-Evolution
A common critique of native agent frameworks is that including too many specialized skills bloats the system prompt. In practice, however, a structured, natively integrated vocabulary of skills is the only way to guide the agent reliably.
Hermes features a mechanism for automatic skill evolution:
- When the agent detects a recurring workflow (e.g., scraping and cleaning specific market APIs), it programmatically extracts the logic and writes it as a new
.mdskill file in its local library. - On subsequent runs, the agent loads this specialized skill directly, shortening a 3-minute manual execution down to 10 seconds and significantly lowering inference costs.
Below is an example schema of a generated skill descriptor:
# Skill: fetch-market-spread
- Trigger: user asks for cryptocurrency spreads
- Dependencies: @mcp/ethers, @mcp/fetch
- Executable: scripts/calculate_spread.js4. Memory Routing: Reflect vs. Recall
To provide long-term utility, personal agents require persistent memory. When integrating the memory provider Hindsight to help Hermes track cross-session state, we initially made the mistake of over-relying on Hindsight’s Reflect mechanism.
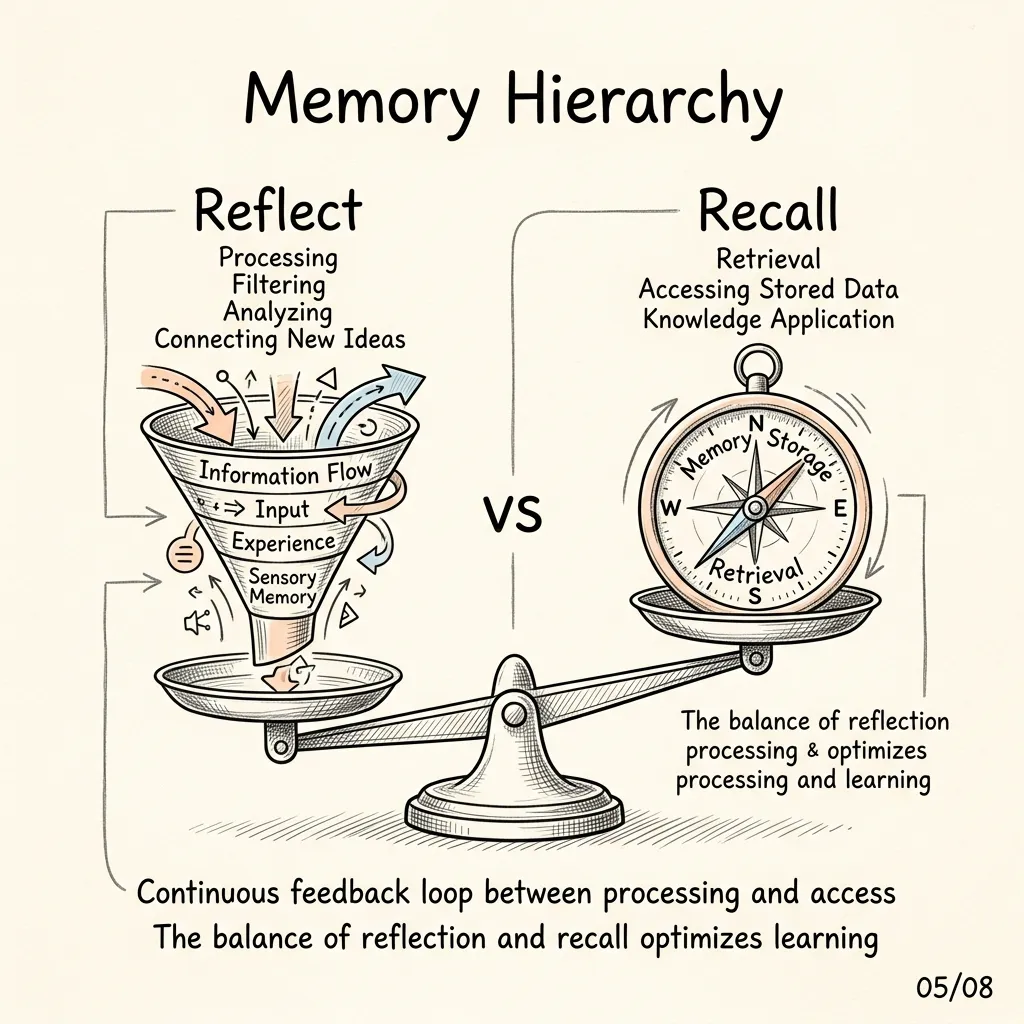
Hindsight separates retrieval into two distinct patterns:
- Reflect (Deep Reasoning): The agent analyzes all past sessions to synthesize structural relationships. Reflect is computationally expensive, often taking over 240 seconds, and regularly triggers API timeout errors. Running Reflect on automated daily cron jobs cost us $20 to $30 a day.
- Recall (Fast Lookup): Retrieves specific historical facts with minimal token usage. For time-sensitive cron jobs (e.g., daily market briefs), routing queries to Recall instead of Reflect avoids timeouts and reduces operational costs.
5. The 6-Step Agent Feedback Loop
The fastest path to aligning a personal agent is establishing a tight feedback loop. We run Hermes daily at 10 AM to scrape X (Twitter) feeds, newsletters, and portfolio updates, synthesizing them into a structured brief.
We refined the output format using a 6-step loop:
- Produce: Hermes generates a draft brief.
- Flag: The user reviews the output and flags irrelevant noise.
- Correct: The user provides a specific correction or layout constraint.
- Encode: Hermes converts this feedback into permanent rules in
User.mdorSoul.md. - Tighten: The next iteration runs with a stricter focus.
- Repeat: The output gets cleaner with every cycle.
Note: A remaining challenge is the Echo Chamber Effect, where the agent’s “Why It Matters” sections tend to gravitate exclusively toward existing holdings (e.g., Nvidia, TSMC), reinforcing pre-existing biases. Resolving this requires introducing contrarian search agents to deliberately seek opposing data.
6. x402 Micropayments: Unlocking Premium Data
Traditionally, equipping an agent with paid APIs (e.g., Nansen, Firecrawl, Exa) required manually managing multiple monthly subscriptions, even for occasional, one-off research tasks.
The x402 protocol (leveraging the HTTP 402 Payment Required status) solves this subscription bottleneck.
- Agentic Wallet: The agent is provisioned with a programmatic, non-custodial wallet (e.g., Coinbase CDP or Circle MPC) funded with a small USDC balance.
- Per-Query Settlement: When requesting data from a premium API, the server responds with a
402 Payment Requiredstatus. The agent’s wallet signs the EIP-3009 payment payload, pays a few cents on-chain, and immediately retrieves the data. - Result: The agent accesses premium datasets on-demand, transforming operational costs from static monthly overhead to per-query micropayments.
7. Codebase Structure: Skill Bundling
To prevent prompts from growing into unmaintainable spaghetti text, technical skills should be treated as structured directories rather than long system instructions.
Standard Skill Bundle Directory:
onchain-dump-investigation/
├── SKILL.md # Core pipeline instructions (under 100 lines)
├── references/ # Static API schemas & Rate Limit patterns
│ ├── nansen-endpoints.md # Schema definitions and quirks
│ └── cookie-queries.md # Multi-chain query templates
└── scripts/ # Executable scripts
└── check_wallets.sh # Bash script for wallet analysisThis structural separation provides distinct advantages:
- Clean Context: Loading the main pipeline instructions requires only 500 tokens, keeping the context window focused.
- Reference Isolation: Technical details like endpoint URLs and error-handling scripts are only loaded when the agent explicitly decides to execute the tool.
8. Horizontal Comparison: Hermes vs. OpenClaw
Based on our implementation, we compiled a comparison matrix between Nous Research’s Hermes and OpenClaw:
| Feature | Hermes Agent (Nous Research) | OpenClaw |
|---|---|---|
| Design Philosophy | Self-growing cognitive capability | Platform connectivity & integration |
| Core Advantage | Auto-encapsulates new skills locally from experience | Out-of-the-box support for Slack, Discord, etc. |
| Memory System | Rich native memory files combined with Hindsight | Simple markdown memory blocks for short-term state |
| Security Model | Strong; local execution limits supply-chain attacks | Moderate; requires manual review of community plug-ins |
| Best Fit | Deep, long-running research tasks requiring learning | Immediate task routing across multiple consumer channels |
9. The Determinism Contract & Verification
To verify that the agent’s execution is deterministic across different machines and environments, we run cryptographic hash checks on the output files:
Verification Commands:
On Linux / macOS (Bash):
# Compare the SHA-256 hashes of two separate execution reports
sha256sum report-a.json report-b.jsonOn Windows (PowerShell):
# Verify deterministic output hashes
Get-FileHash report-a.json
Get-FileHash report-b.jsonIf the hashes match exactly, it proves the skill bundling and environment mock setups successfully isolated the agent’s runtime from wall-clock variance.
10. Architectural Boundaries & Final Assessment
Strong Fit For:
- Structured Research: Long-running, automated analysis tasks (e.g., daily market briefs, risk modeling).
- Self-Contained Security: Private workflows where third-party data leaks must be minimized.
- Developer-led Ops: Teams comfortable maintaining local shell scripts and API reference schemas inside their repository.
Less Compelling For:
- Ad-hoc Tasks: Simple, one-off web scrapes that do not benefit from persistent memory.
- Non-technical Users: Workflows that require no-code visual builders rather than codebase-oriented skill bundles.
Useful agent engineering is not about purchasing the most expensive frontier model API. It is defined by isolated skill directories, decoupled memory paths, and pay-as-you-go micropayment architectures.
