用 Obsidian 搭一个会自己运转的第二大脑
用 Obsidian 搭一个会自己运转的第二大脑
大多数人的第二大脑,最后都会变成一个更大的“待整理”。
问题不在 Obsidian,也不在 Zettelkasten、PARA、Daily Note 或双链笔记。这些方法真正依赖一个隐藏前提:你必须长期、稳定、免费地扮演自己的资料管理员。
你要负责归档文章、拆解观点、补链接、处理冲突、定期回顾、合并旧笔记。只要连续忙几天,系统就开始失控:收藏越来越多,能复用的知识越来越少。
所以,第二大脑真正缺的不是更漂亮的文件夹,而是一个能自动运转的后台班组。
这篇文章给出一套可落地的设计:用 Obsidian 的本地 Markdown 仓库做底座,用 Agent 做夜间处理,把“捕捉”留给人,把“整理、拆解、链接、审查、汇总”交给自动化流程。
你白天只负责把东西扔进入口文件夹。晚上,Agent 按角色分工处理。第二天早上,你拿到一份简报:昨晚新增了什么、哪些观点互相冲突、哪些主题线程变完整了,以及今天最值得你处理的一件事。
TL;DR: 不要把第二大脑设计成聊天机器人,而要设计成一个本地研究部门。人负责判断和捕捉,Agent 负责夜间加工、巡检和提醒。
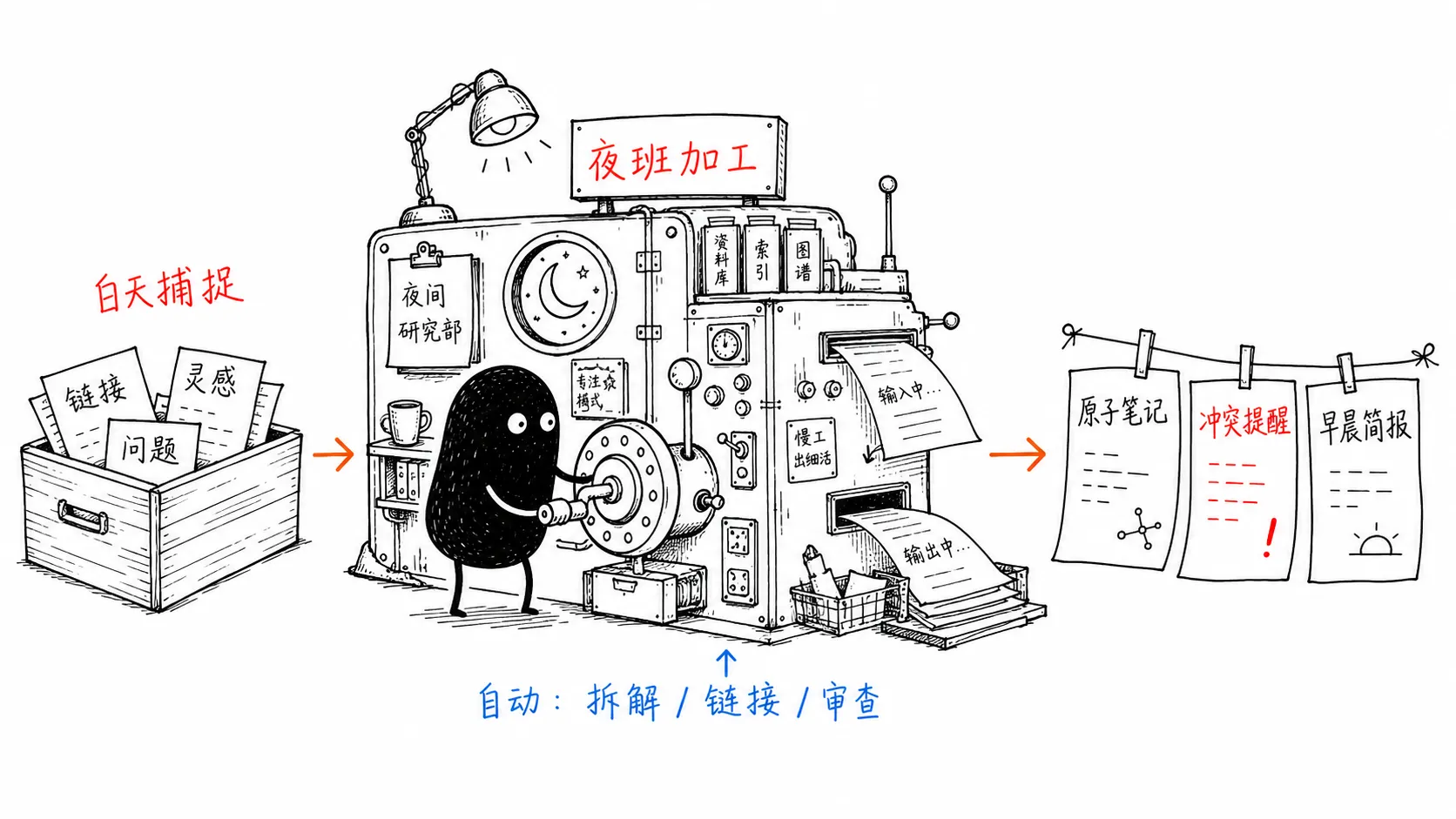
先说结论:你的第二大脑需要一个夜班
不要把第二大脑想成一个笔记 App。
更准确的模型是:它是一个小型研究部门。你是白班,Agent 是夜班。
白天,人做最擅长的事:
- 看到有价值的文章
- 捕捉一段灵感
- 记录一个判断
- 保存一个问题
- 标记一个值得以后深入研究的线索
这些输入可以很粗糙,甚至可以只是几句话。关键不是一开始就整理好,而是先把原料放进系统。
晚上,夜班接手:
- 把链接里的全文抓回来
- 把长文章拆成多个独立观点
- 查找相关旧笔记
- 建立双向链接
- 标记和旧观点冲突的地方
- 更新综合主题文档
- 生成第二天的阅读简报
这套系统的产品目标很简单:
人负责判断和捕捉,机器负责整理和巡检。
它不是为了让你少记笔记,而是为了让你少做低价值整理,把注意力留给真正重要的判断。
这套系统适合谁,不适合谁
它适合三种人:
- 长期收藏资料的人:你经常保存文章、论文、播客、视频、灵感,但很少回头整理。
- 需要持续写作的人:你希望 Obsidian 不只保存素材,还能提醒你哪些主题值得展开。
- 愿意让 AI 参与知识加工的人:你不追求全自动写作,但希望 Agent 帮你做检索、拆解、链接和冲突检查。
它不适合两类人:
- 只想手动整理的人:如果你享受每周手动回顾和归档,这套系统可能过度设计。
- 完全不想审查 AI 输出的人:这套系统的底线是可信,不是无脑自动化。没有人工审查,知识库很快会被幻觉和错误链接污染。
角色设计:不是一个聊天机器人,而是一支研究小组
如果只是让一个 AI 聊天窗口帮你“整理笔记”,它很快会变成另一个需要你反复指挥的工具。
更稳定的做法,是把夜间流程拆成不同角色。每个角色只做一类任务,边界清楚,结果可检查。
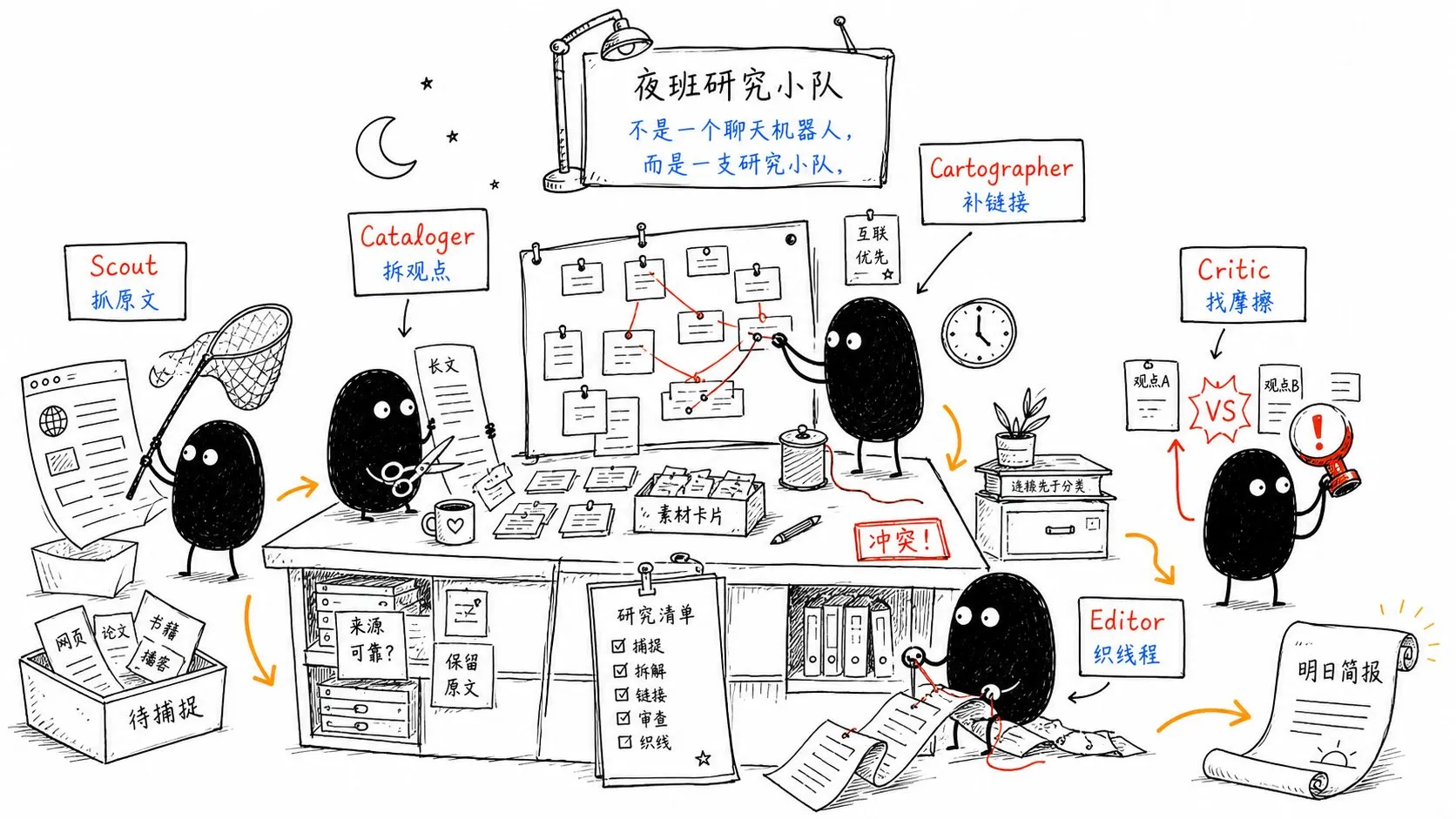
1. Scout:侦察员
Scout 负责外部资料获取。
它读取你的阅读清单,打开网页、论文、博客、PDF,把原始内容保存到 sources/。它只做一件事:尽可能完整地把资料带回来,不总结、不改写、不判断。
2. Cataloger:编目员
Cataloger 负责把原始资料拆成原子笔记。
一篇文章可能包含 8 个观点,那就生成 8 条原子笔记。每条笔记只承载一个核心想法,并且必须能追溯到来源。
3. Cartographer:制图员
Cartographer 负责维护知识地图。
每生成一条新笔记,它都要查找相关旧笔记,建立链接。这样 Obsidian 里的双链不再只是好看的图谱,而是真正可导航的思考网络。
4. Critic:审查员
Critic 是整套系统里最重要的角色。
它不负责让内容更顺滑,而是负责找摩擦:
- 新笔记是否和旧笔记冲突?
- 某个判断有没有来源?
- 旧结论是否被新材料削弱?
- 有没有看似合理但来源不足的推断?
它不会自动替你做最终判断,只会把冲突标记出来,让你在简报里处理。
5. Editor:编辑
Editor 负责综合。
它把多个相关原子笔记编织成主题线程,比如“电池成本曲线”“AI Agent 工作流”“个人知识管理系统”。这些线程不是静态文章,而是会随着新材料进入系统持续更新的活文档。
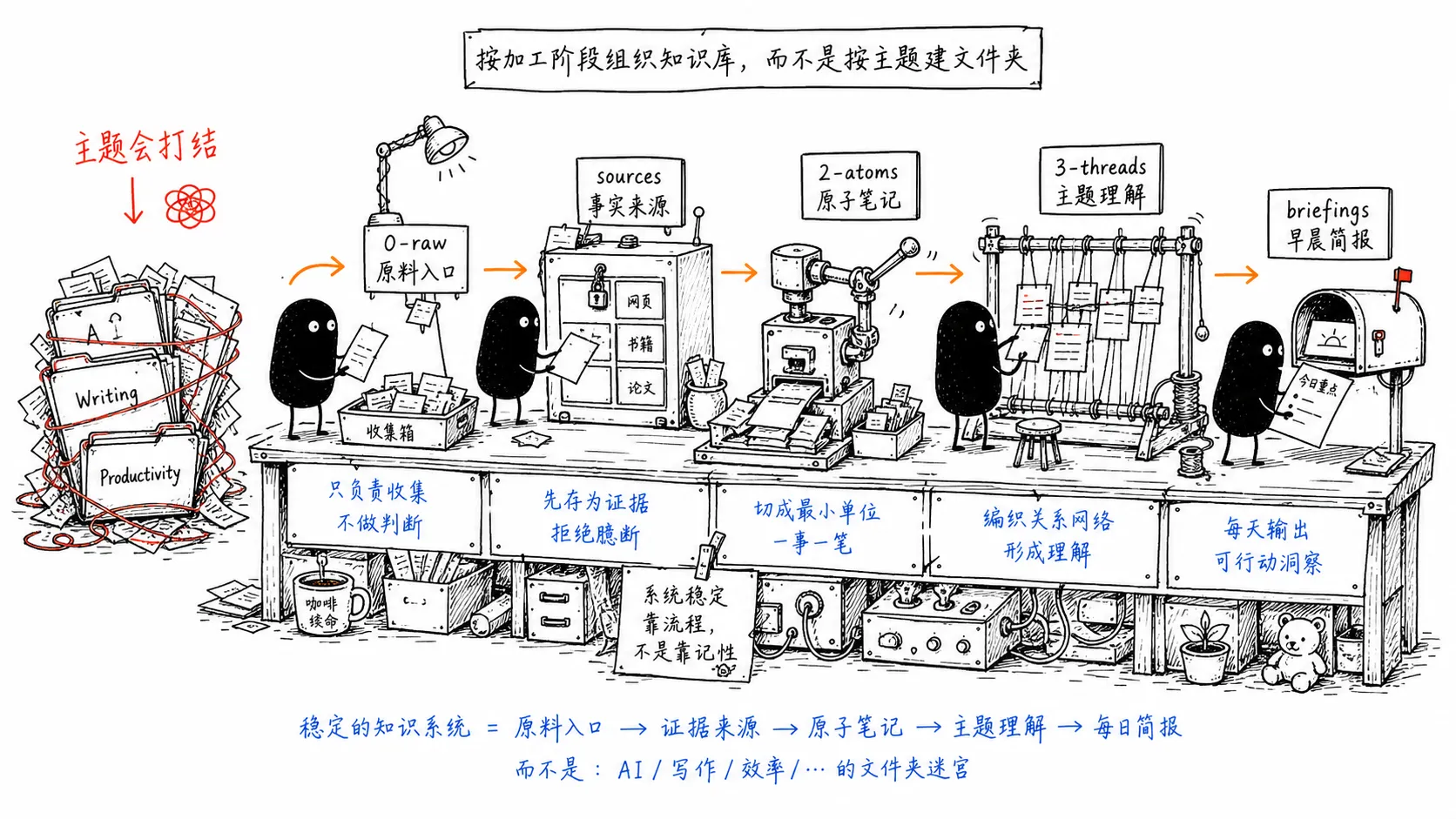
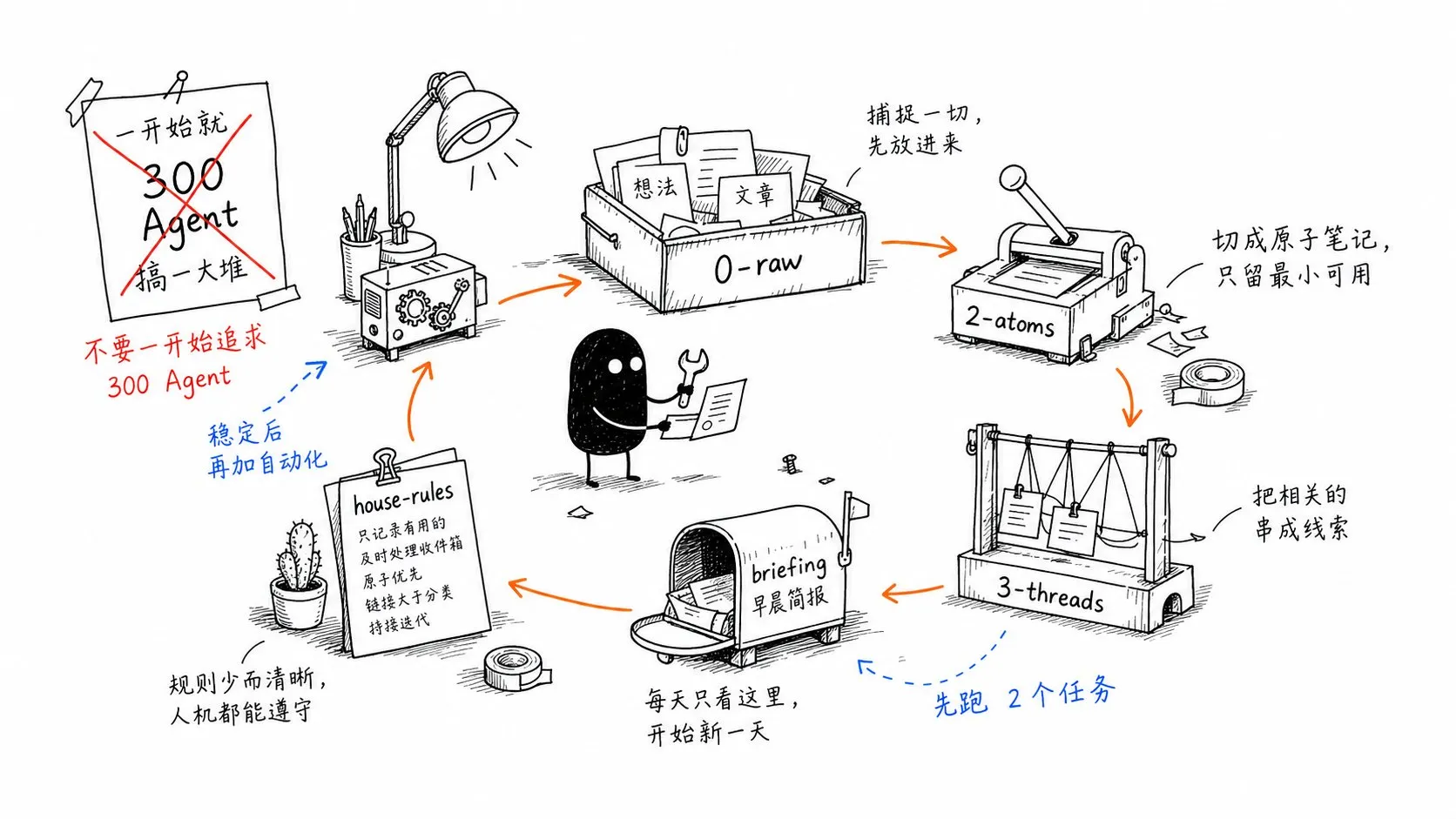
目录结构:按加工阶段组织,而不是按主题分类
很多人的知识库一开始就按主题建文件夹:
AI/
Productivity/
Writing/
Investing/
Health/这看起来清晰,但很快会出问题。真实知识经常跨主题,一个观点可能同时属于 AI、写作和生产力。如果强迫它只待在一个文件夹里,你只是把整理压力换了个地方。
更适合 Agent 的结构,是按“加工阶段”组织:
brain/
├── 0-raw/ # 原始输入:想法、链接、摘录、临时记录
├── 1-desk/ # Agent 工作区:处理中间文件
├── 2-atoms/ # 原子笔记:一个文件一个想法
├── 3-threads/ # 主题线程:由多个原子笔记综合而成
├── sources/ # 原文归档:文章、网页、PDF 的只读副本
├── briefings/ # 每日简报和每周审计报告
├── playbooks/ # Agent 的任务说明书
└── house-rules.md # 所有 Agent 必须遵守的规则这个结构的关键,是让每个文件都有明确身份。
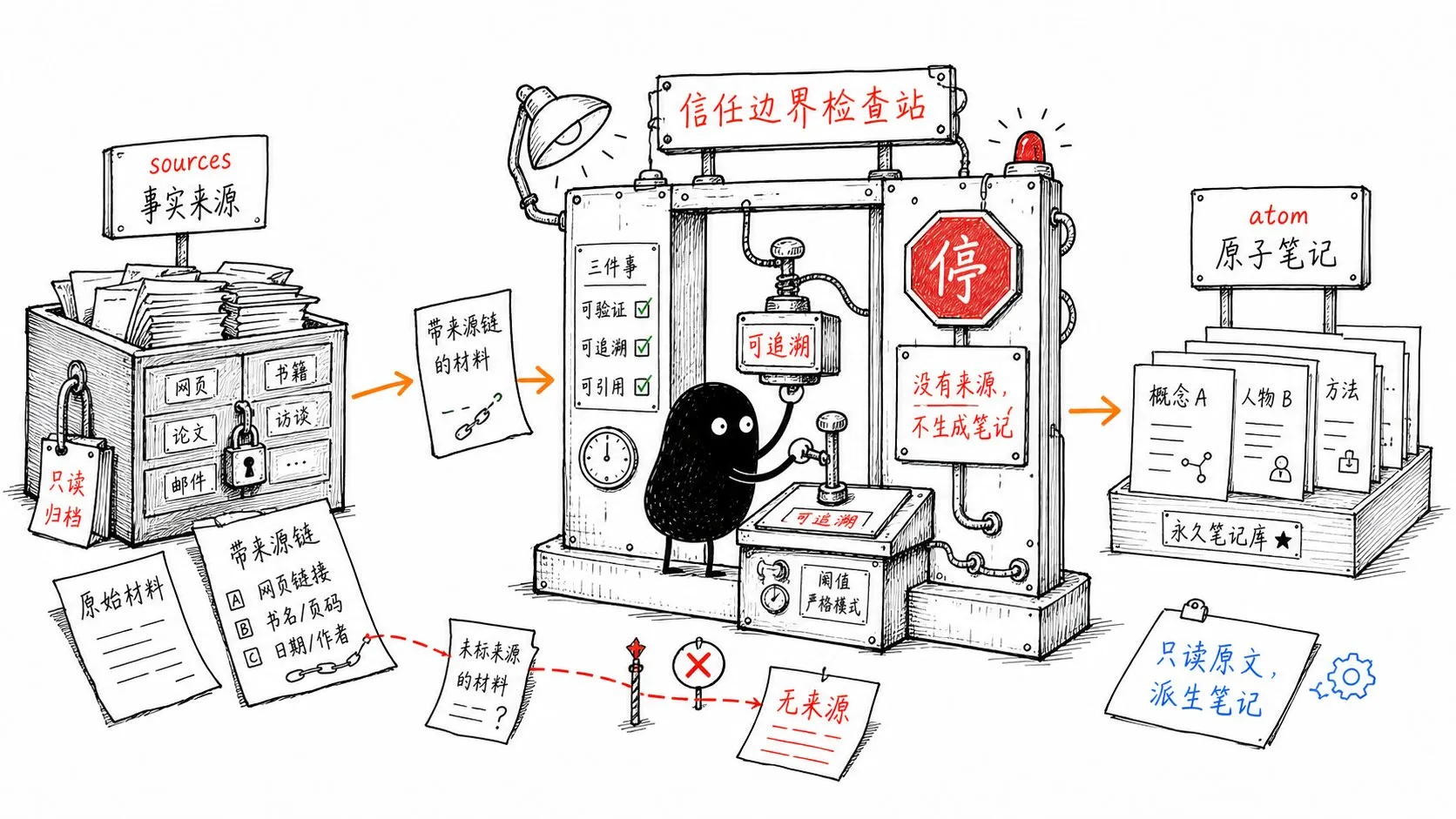
0-raw/ 和 sources/ 不允许被改写
原始输入和原文资料是整个系统的事实来源。
Agent 可以读取它们,可以从中派生笔记,但不能擅自修改。否则知识库会出现一个危险问题:新笔记引用旧笔记,旧笔记又来自 AI 的总结,几轮之后你已经分不清哪些是原文事实,哪些是模型补出来的内容。
2-atoms/ 只放原子笔记
原子笔记的标准是:一个文件只表达一个观点。
这会让链接、冲突检测和主题综合都更准确。长文档适合阅读,不适合被系统长期复用。原子笔记才是第二大脑真正的可组合零件。
3-threads/ 承载理解
原子笔记是材料,主题线程才是理解。
比如你不断收集关于 Obsidian、MCP、Agent、知识管理的笔记,Editor 会持续维护一个“自动化第二大脑”线程,把相关材料组织成结构化观点。这层内容才是以后写文章、做决策、复盘项目时最有价值的部分。
1-desk/ 是临时工作台
Agent 在处理过程中会产生中间文件、草稿、待合并结果。它们不应该污染永久笔记区。
每次夜班结束后,1-desk/ 应该被清空或归档。
先写规则:house-rules.md
在让 Agent 自动处理笔记之前,必须先写清楚边界。
一个可用的 house-rules.md 可以这样开始:
# House Rules
## Pipeline
- 0-raw/:只读入口,不修改原始捕捉。
- 1-desk/:临时工作区,任务结束后清理。
- 2-atoms/:永久原子笔记,一个文件一个观点。
- 3-threads/:主题综合文档,优先更新已有线程。
- sources/:原始资料归档,只读。
- briefings/:写给用户的简报。
## Prime Directive
每条原子笔记都必须能追溯到 0-raw/ 或 sources/ 中的真实来源。
没有来源,不生成笔记。
不能用“看起来合理”的内容补足材料空白。
## Working Rules
1. 一个 atom 只表达一个观点。
2. 创建新 atom 前,先搜索是否已有相近笔记可以扩展。
3. 每个 atom 至少链接两个相关笔记;如果暂时找不到,标记为待审查。
4. 新观点与旧观点冲突时,添加 [FRICTION] 区块,不要静默覆盖。
5. 不删除旧笔记;过时内容标记为 [RETIRED] 并移入 archive。
6. 每次任务结束后,更新相关 thread,并写入 briefing。
## Authority
Agent 只能写入 1-desk/、2-atoms/、3-threads/ 和 briefings/。
任何破坏性操作、批量改名、删除、覆盖,都必须暂停并请求人工确认。这里最重要的是 Prime Directive:没有来源,不生成笔记。
这条规则决定你的第二大脑最终是可信的知识系统,还是一堆听起来很顺的幻觉摘要。
一个完整夜班长什么样
假设你白天在 0-raw/ 里随手保存了一条想法:
钠离子电池如果真的能把整包成本做到 56 美元/kWh,
那“锂资源会卡住电动车普及”的判断可能需要重新评估。
需要和之前保存的电池成本曲线资料对照。你不需要整理它,也不需要马上找资料。晚上 Agent 自动处理。
第二天,2-atoms/ 里可能会出现一条这样的笔记:
---
id: 2026-0617-sodium-ion-cost-parity
type: atom
certainty: tentative
sources:
- sources/2026-06-17-sodium-ion-pack-cost.md
links:
- "[[battery-cost-curves]]"
- "[[lithium-supply-bottleneck-thesis]]"
- "[[lfp-battery-chemistry]]"
---
## Claim
如果量产钠离子电池包成本接近 56 美元/kWh,
它可能削弱“锂资源成本是电动车普及主要瓶颈”的判断。
## Why It Matters
电池成本曲线会直接影响电动车价格、储能系统经济性和上游资源假设。
## [FRICTION]
[[lithium-supply-bottleneck-thesis]] 中把锂资源成本视为主要约束。
当前材料对这个判断构成压力。两者不能同时完全成立,需要人工判断。
## Open Questions
- 56 美元/kWh 是补贴后价格,还是可持续量产成本?
- 钠离子电池能量密度较低,是否会抵消成本优势?
- 这个成本是否只适用于特定车型或供应链条件?同时,briefings/2026-06-18.md 里会出现一条提示:
### Contradictions You Should Resolve
- 新增钠离子电池成本笔记与 [[lithium-supply-bottleneck-thesis]] 冲突。
建议今天判断:锂资源瓶颈是否仍是电动车普及的核心假设?这就是系统真正有价值的地方。
它不只是保存你的想法,而是把你的新输入和旧判断放在一起比较,提醒你哪里需要重新思考。
四个 Playbook:把夜班拆成可执行任务
你不应该让一个大任务负责所有事情。更稳定的方式是把夜间流程拆成四个定时任务。
1. Scout Run:晚上 11 点抓取资料
# Scout Run
## Job
读取 0-raw/reading-list.md 中的链接。
对每个链接:
1. 打开网页并提取正文。
2. 原样保存到 sources/YYYY-MM-DD-{slug}.md。
3. 添加 frontmatter:url、captured_at、word_count。
4. 在 0-raw/ 中留下待处理指针。
## Rules
- 只抓取,不总结。
- 抓取失败时记录 [UNREACHABLE],不要卡住整个任务。
- 不修改 reading-list.md 原文。2. Refinery Run:凌晨 3 点拆解和链接
# Refinery Run
## Job
处理 0-raw/ 中所有未处理材料。
对每个材料:
1. 读取原始捕捉和相关 source。
2. 拆成多个原子笔记。
3. 创建前先搜索是否已有相近 atom。
4. 为每个 atom 添加相关链接。
5. 检查是否与旧笔记冲突。
6. 有冲突则添加 [FRICTION],不自动覆盖。
7. 处理完成后,把原始捕捉归档。
## Hard Rules
- 遵守 Prime Directive。
- 不改写 sources/。
- 遇到不确定合并,标记给人工处理。3. Editor Run:早上 6 点写简报
# Editor Run
## Job
1. 找出过去 24 小时新增或修改的 atom。
2. 更新相关 3-threads/ 主题线程。
3. 写入 briefings/YYYY-MM-DD.md。
## Briefing Format
### What Came In
### Contradictions You Should Resolve
### Threads That Grew
### One Thing Worth Your Attention Today4. Audit Run:每周日晚做健康检查
# Audit Run
## Job
扫描整个知识库并生成 briefings/audit-YYYY-MM-DD.md:
1. 没有入链或出链的孤立 atom。
2. certainty: tentative 且 14 天未复查的笔记。
3. 超过 7 天未处理的 [FRICTION]。
4. 没有 sources 字段的 atom。
5. 30 天未更新、但仍有新增材料相关的 thread。
## Rule
只报告,不自动修复。对应的定时计划可以是:
0 23 * * * Scout Run
0 3 * * * Refinery Run
0 6 * * * Editor Run
0 22 * * 0 Audit Run这个节奏的好处是:抓取、拆解、综合、审计互相独立,出问题时也容易定位。
可以用什么 Agent 实现
原文提到的方案基于 Kimi Work:一个本地桌面 Agent,公开资料称它面向本地文件、真实浏览器会话和多 Agent 并行工作流。根据 2026 年 6 月的公开报道,Kimi Work 与 Kimi K2.6、WebBridge、Agent Swarm 等能力相关,部分资料提到最多 300 个子 Agent 和 4,000 步协同任务。
但落地时不应该把“300 Agent”当成必需条件。
这套架构真正依赖的是四种能力:
- 能读取和写入本地 Markdown 文件。
- 能按计划定时运行任务。
- 能调用浏览器或抓取网页正文。
- 能把任务拆分并并行处理,至少可以批量处理多个文件。
所以除了 Kimi Work,你也可以用其他本地 Agent、脚本、MCP Server、Obsidian 插件或自动化工具拼出类似流程。关键不是工具品牌,而是规则、目录、权限和可验证的处理结果。
最重要的安全边界
让 Agent 自动读写你的知识库,收益很大,风险也不小。
下面这些规则建议从第一天就做。
1. 给知识库上 Git
在 brain/ 根目录初始化 Git。
每次夜班结束后自动提交一次,提交信息包含日期和任务摘要。这样一旦 Agent 错改、误合并或污染笔记,可以直接回滚。
2. 初期保持人工确认
不要一开始就全自动。
先让 Agent 生成草稿和简报,你确认几轮后再逐步开放写入权限。尤其是删除、覆盖、批量移动文件,一律需要人工确认。
3. 定期处理 [FRICTION]
冲突不处理,系统会越来越吵。
每周留 20 分钟看 Audit 报告,处理那些超过 7 天的 [FRICTION]。这是人类最应该保留的工作:判断哪个观点更新、更可靠,或者两个观点是否适用于不同条件。
4. 审查无来源笔记
没有来源的笔记要么补来源,要么降级为个人想法,要么归档。
不要让“无法追溯来源的结论”混进永久知识层。
5. 不要给 Agent 过大的写入权限
一开始不要让它直接改 3-threads/ 里的成熟主题文档。更安全的做法是:
- 先写入
1-desk/草稿 - 在简报中展示差异
- 你确认后再合并到
3-threads/
权限要随着信任逐步放开。
这套系统真正会改变什么
第一层变化很明显:你不再需要手动整理所有材料。
以前你收藏 20 篇文章,后面真正会整理的可能只有 2 篇。现在你只需要把它们放进入口,系统会自动拆成可复用的知识块。
第二层变化更关键:系统会开始提醒你和自己发生冲突。
人很难记住三个月前写过的每个判断。Agent 可以。它会告诉你:“你今天保存的观点,和你之前关于同一主题的结论不一致。”这比单纯搜索笔记更有价值。
第三层变化是复利。
当 3-threads/ 持续更新几个月后,你会发现很多主题文档已经比你的即时记忆更完整。它们不是凭空生成的百科,而是从你自己读过、写过、判断过的材料里长出来的结构化理解。
这才是第二大脑的意义:不是帮你囤积资料,而是帮你保留和升级判断。
最小可行版本
如果你不想一开始搭完整系统,可以先做 MVP:
brain/
├── 0-raw/
├── 2-atoms/
├── 3-threads/
├── sources/
├── briefings/
└── house-rules.md然后只实现两个任务:
- 每晚处理
0-raw/,生成2-atoms/。 - 每天早上生成一份
briefings/YYYY-MM-DD.md。
等这个流程稳定后,再加 Scout、Editor、Audit,以及浏览器抓取、MCP、Git 自动提交。
不要一开始追求“300 个 Agent”。先让 3 个文件夹和 2 个任务稳定运转,你已经超过了大多数人的第二大脑系统。
30 分钟启动清单
如果你想今天就开始,可以按这个顺序做:
- 新建
brain/仓库。 - 创建
0-raw/、2-atoms/、3-threads/、sources/、briefings/。 - 写入
house-rules.md,先保留 Prime Directive。 - 手动放 3 条真实输入到
0-raw/。 - 让 Agent 只生成草稿,不直接写入永久目录。
- 你确认 1 条原子笔记,再允许它写入
2-atoms/。 - 第二天看简报,判断这套流程是否真的省时间。
如果 7 天后你发现简报比 Obsidian 原生搜索更能提醒你该看什么,这套系统就值得继续自动化。
